
Apache Kafka introduction
- Jun 13, 2020
- 7 min read
In this article we will take a look at the famous open source Apache Kafka for the Data Integration task. We will discuss following topics about Kafka:
Introduction to Apache Kafka
Use Cases and real world examples of Apache Kafka
Architecture of Apache Kafka: (producer, broker, consumer, topic)
Introduction to Apache Kafka
Kafka was developed around 2010 at LinkedIn by a team that included Jay Kreps, Jun Rao, and Neha Narkhede to solve was low-latency ingestion of large amounts of event data from the LinkedIn website and infrastructure into a lambda architecture that harnessed Hadoop and real-time event processing systems. Now we will take a look at what exactly Kafka is.
First what Is a Messaging System?
A messaging system is a system that is used for transferring data from one application to another so that the applications can focus on data and not on how to share it.
Apache Kafka:
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation
written in Scala and Java.
Aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Its storage layer is essentially a “massively scalable pub/sub (publication or Subscribe) message queue designed as a distributed transaction log,” making it highly valuable for enterprise infrastructures to process streaming data.
Kafka can also connect to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
The design is heavily influenced by “transaction logs“
What is “transaction logs”?
In the field of databases in computer science, a transaction log (also transaction journal, database log, binary log or audit trail) is a history of actions executed by a database management system used to guarantee ACID properties over crashes or hardware failures.
Physically, a log is a file listing changes to the database, stored in a stable storage format.
If after a start, the database is found in an inconsistent state or not been shut down properly, the database management system reviews the database logs for uncommitted transactions and rolls back the changes made by these transactions.
Additionally, all transactions that are already committed but whose changes were not yet materialised in the database are re-applied. Both are done to ensure atomicity and durability of transactions.
Therefore the log data structure is : The log is simply a time-ordered, append-only sequence of data inserts where the data can be anything (in Kafka, it’s just an array of bytes).
Use cases of Apache Kafka
Following are the some of the important use cases of Kafka
Data Pipelines
Modern ETL or CDC (Change Data Capture)
Big Data Ingestion
Messaging: used as a message broker among services
Log Aggregation: to collect logs from different systems and store in a centralised system for further processing
Activity Monitoring: The activity could belong to a website or physical sensors and devices. Producers can publish raw data from data sources that later can be used to find trends and pattern
Database
Kafka also acts as a database. Not a typical databases that have a feature of querying the data as per need, what I meant that you can keep data in Kafka as long as you want without consuming it.
Real world examples:
It allows users to subscribe to it and publish data to any number of systems or real-time applications. Real world example where Apache Kafka is used are:
Managing passenger and driver matching at Uber,
Providing real-time analytics and predictive maintenance for British Gas’ smart home, and
Performing numerous real-time services across all of LinkedIn.
Big Data ingestion at Netflix

Kafka at Netflix
Kafka at Uber: Managing passenger and driver matching



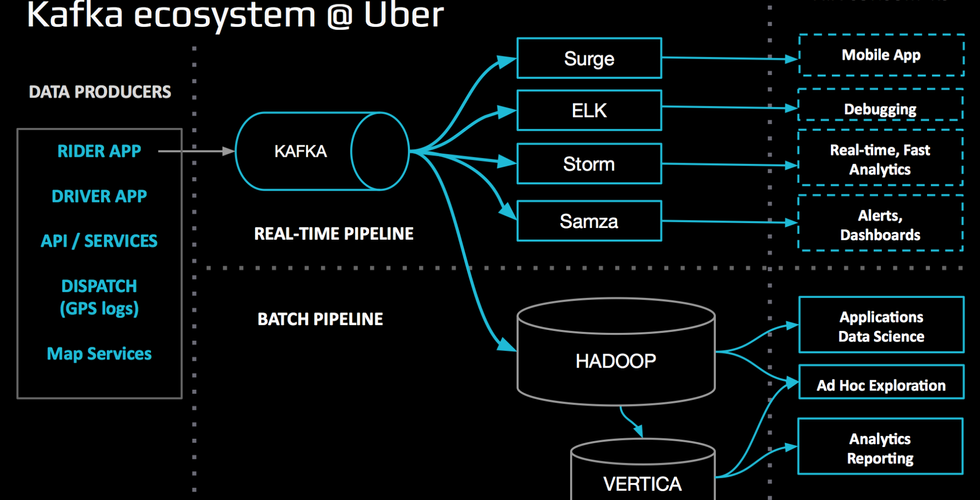




According to Uber website, Uber uses Kafka with uReplication (developed by Uber) as follows:
Uber uses Apache Kafka as a message bus for connecting different parts of the ecosystem
they collect system and application logs as well as event data from the rider and driver apps
Then they make this data available to a variety of downstream consumers via Kafka.
Data flows through Kafka pipelines to power many of Uber’s analytical use cases on the right (as shown in the picture.)
Data in Kafka feeds both real-time pipelines and batch pipelines
Note that Uber uses it’s own uReplicator with Apache Kafka instead of Apache Kafka’s MirrorMaker
Architecture of Kafka (producer, broker, consumer, topic)
Before moving forward let’s understand following basic terms:
In case of the Database server overload problem we can use either Vertical Vs Horizontal scaling. But both have certain limits and issues.
A distributed system is one which is split into multiple running machines, all of which work together in a cluster to appear as one single node to the end user.
Also note that a commit log (also referred to as write-ahead log, transaction log) is a persistent ordered data structure which only supports appends (as shown in the image shown below). You cannot modify nor delete records from it. It is read from left to right and guarantees item ordering. This structure is at the heart of Kafka, it provides ordering, which in turn provides deterministic processing

example commit log
Now with this basic knowledge we will move forward and will take a look at architecture of Apache Kafka:
Kafka is a distributed publish-subscribe messaging system.
In a publish-subscribe system, messages are persisted in a topic.
Message producers are called publishers and
message consumers are called subscribers.
Consumers can subscribe to one or more topic and consume all the messages in that topic
Kafka is distributed in the sense that it stores, receives and sends messages on different nodes (called brokers). Because of this it has high scalability and fault-tolerance.
Kafka actually stores all of its messages to disk (more on that later) and having them ordered in the structure lets it take advantage of sequential disk reads. Therefore Kafka has the same performance whether you have 100KB or 100TB of data on your server

Topics and Partitions in Kafka Cluster
Topics –Every message that is feed into the system must be part of some topic. The topic is nothing but a stream of records. The messages are stored in key-value format. Each message is assigned a sequence, called Offset. The output of one message could be an input of the other for further processing.
Producers –Producers are the apps responsible to publish data into Kafka system. They publish data on the topic of their choice.
Consumers –The messages published into topics are then utilized by Consumers apps. A consumer gets subscribed to the topic of its choice and consumes data.
Broker –Every instance of Kafka that is responsible for message exchange is called a Broker. Kafka can be used as a stand-alone machine or a part of a cluster.
Topics and partitions in Kafka cluster:
Applications (producers) send messages (records) to a Kafka node (broker) and said messages are processed by other applications called consumers.
Said messages get stored in a topic and consumers subscribe to the topic to receive new messages.
Note that Brokers are simple systems responsible for maintaining published data. Kafka brokers are stateless (that is they do not keep any data regarding the processing), so they use ZooKeeper for maintaining their cluster state. We will see it in detail later in this article.
What is offset and partition? Why Partitioning is important? How they can replay or reprocess the events?

Topics
As topics can get quite big, they get split into partitions of a smaller size for better performance and scalability. For example say you were storing user login requests, you could split them by the first character of the user’s username
Kafka guarantees that all messages inside a partition are ordered in the sequence they came in
The way you distinct a specific message is through its offset, which you could look at as a normal array index
Kafka follows the principle of a dumb broker and smart consumer. This means that Kafka does not keep track of what records are read by the consumer and delete them but rather stores them a set amount of time (e.g one day) or until some size threshold is met. Consumers themselves poll Kafka for new messages and say what records they want to read. This allows them to increment/decrements the offset they’re at as they wish, thus being able to replay and reprocess events.
It is worth noting that consumers are actually consumer groups which have one or more consumer processes inside. In order to avoid two processes reading the same message twice, each partition is tied to only one consumer process per group.

Consumer group subscribed to a topic interacting with Partitions
Note that Kafka actually stores all of its records to disk and does not keep anything in RAM. Since the said linear operations are heavily optimised by the OS, via read-ahead (pre-fetch large block multiples) and write-behind (group small logical writes into big physical writes) techniques.
Kafka stores messages in a standardised binary format unmodified throughout the whole flow (producer->broker->consumer), it can make use of the zero-copy optimisation
Data Replication in Kafka:
Partition data is replicated across multiple brokers in order to preserve the data in case one broker dies.
At all times, one broker “owns” a partition and is the node through which applications write/read from the partition.
This is called a partition leader. It replicates the data it receives to N other brokers, called followers. They store the data as well and are ready to be elected as leader in case the leader node dies. In this way, if one leader ever fails, a follower can take his place.
For a producer/consumer to write/read from a partition, they need to know its leader and Kafka stores such metadata in a service called Zookeeper.

Data Replication
What is Zookeeper? Why we need Zookeeper with Kafka?








Is a distributed key-value store
highly-optimised for reads but writes are slower
most commonly used to store metadata and handle the mechanics of clustering (heartbeats, distributing updates/configurations, etc)
It allows clients of the service (the Kafka brokers) to subscribe and have changes sent to them once they happen. This is how brokers know when to switch partition leaders. Zookeeper is also extremely fault-tolerant and it ought to be, as Kafka heavily depends on it.
It is used for storing all sort of metadata
Producer and Consumers used to directly connect and talk to Zookeeper to get this (and other) information. Kafka has been moving away from this coupling and since versions 0.8 and 0.9 respectively, clients fetch metadata information from Kafka brokers directly, who themselves talk to Zookeeper.
Stream Processing (Transforms-Data cleaning):

In Kafka, a stream processor is anything that takes continual streams of data from input topics, performs some processing on this input and produces a stream of data to output topics (or external services, databases, the trash bin, wherever really…)
It is possible to do simple processing directly with the producer/consumer APIs, however for more complex transformations like joining streams together, Kafka provides a integrated Streams API library.
This API is intended to be used within your own codebase, it is not running on a broker. It works similar to the consumer API and helps you scale out the stream processing work over multiple applications (similar to consumer groups).
That’s is it for this article. In this article we saw introduction to Apache Kafka, How it works briefly also some use cases. In addition to this I want to share the following useful video:
Neha Narkhede (one of the developer of Kafka at LinkedIn) talks about the experience at LinkedIn moving from batch-oriented ETL to real-time streams using Apache Kafka
If you have any questions feel free to ask in the comment section below. Also if you like this article please like and subscribe to my blog 🙂

Comments